
【初心者向け】もう一度最初から触るAmazon RDS

こんにちは。まると(@MaruDevG)です。
皆さんはデータベースを触ったことはありますか?自分の初データベースは学生時代のMySQLでした。
データベースを触ったことがある方・触ったことがない方もこれから触る方向けに、より簡単かつ運用の負担が減るものがあります。
その一つが、Amazon Relational Database Service(通称、Amazon RDS)です。
Amazon RDSとは
フルマネージド型のリレーショナルデータベースサービスです。
本来、データベースの運用にはサーバー自体のOSやミドルウェアのパッチ適用など、データベースを使用する以外に様々な管理を行う必要がありますが、フルマネージド型サービスのためインフラ面やパッチの管理を行うことなく、データベースの利用ができます。
なお、本記事執筆時点(10/21)では、以下のエンジンに対応しています。
- MySQL
- MariaDB
- PostgreSQL
- Oracle Database
- Microsoft SQL Server
- IBM Db2
- Amazon Aurora(MySQL、PostgreSQL互換データベース)
何が嬉しいの?
前章と重なる部分もありますが、主に以下のメリットがあります。
インフラの管理が不要
タイトルの通り、インフラ部分(物理サーバー、ネットワークなど)の管理が不要となります。
例えば、可用性を上げるには物理サーバーを2台配置、電源・ネットワークの冗長化、DBの同期を取るといった運用前のセットアップ、準備だけでなく運用後も電源・ネットワークなどの監視などが必要となりますが、これらの物理的な機器・インフラはAWSが管理を行うため、初期コストや監視コストなどを削減することができます。
特にマルチAZ(アベイラビリティーゾーン)配置などを行うことによりDBの内容はレプリケーションしながら、障害時でも停止時間を抑えながらデータベースを運用し続けるなどの耐障害性や可用性向上の面でも恩恵を受けることができます。
また、性能過不足やディスク容量が不足した場合でも、すぐに割り当ての変更を行うことができます。
オンプレミスであれば機器の交換、バックアップ&復元などの作業が入りますが、すぐに欲しい性能を調達して運用することができます。
OSやミドルウェアのパッチ管理が不要or容易に
通常、データベースの稼働OSやミドルウェアのアップデートなどインフラ以外でもメンテナンスは必要となります。
Amazon RDSではユーザはOSに直接アクセスできず、OSやミドルウェアなどデータベース以外の要素はAWS側で管理します。
そのため、OS等のパッチ適用はユーザ側で管理する必要はありません。また、メンテナンスウィンドウと呼ばれる機能を使用すること、メンテナンス時間を指定することができるため、アプリケーションへの影響を最小限にすることもできます。
バックアップが容易に
データベースのバックアップについてもAWSの自動バックアップ機能を利用することで簡単に取得することができます。
自動バックアップではポイントインタイムスナップショットとなるため、ポイントインタイム復元(Point-In-Time Recovery、PITR)が可能となります。
これによりスナップショットの作成時点以前の任意の時間の状態に復元することができます。
その他、手動でデータベースのスナップショットを作成することでフルバックアップを取得することができます。
手動バックアップの場合、シングルAZ DB(単一アベイラビリティーゾーンにデータベースを構築)の場合I/Oが一時的に中断することがあります。そのため、本番サービスでのバックアップ実施時には、事前に適切なタイミングを選定するか、マルチAZ構成を採用することでI/O中断を回避することができます。
※ マルチAZの場合、多くのDBエンジンではスタンバイデータベースから取得されるため、I/Oの中断は発生しません。ただし、SQL Serverの場合はI/O中断が発生します。
データベースを構築して接続してみる
では、実際にAWS上にデータベースを構築して接続までしていきたいと思います。
今回の前提条件は以下のものとします。
- VPCが構築済み
- マルチAZかつ、プライベートサブネットに配置
- データベースへの接続はCloudShellから行う
- CloudShell、RDS間のセキュリティグループを作成済み
また、今回の構成図を以下に示します。
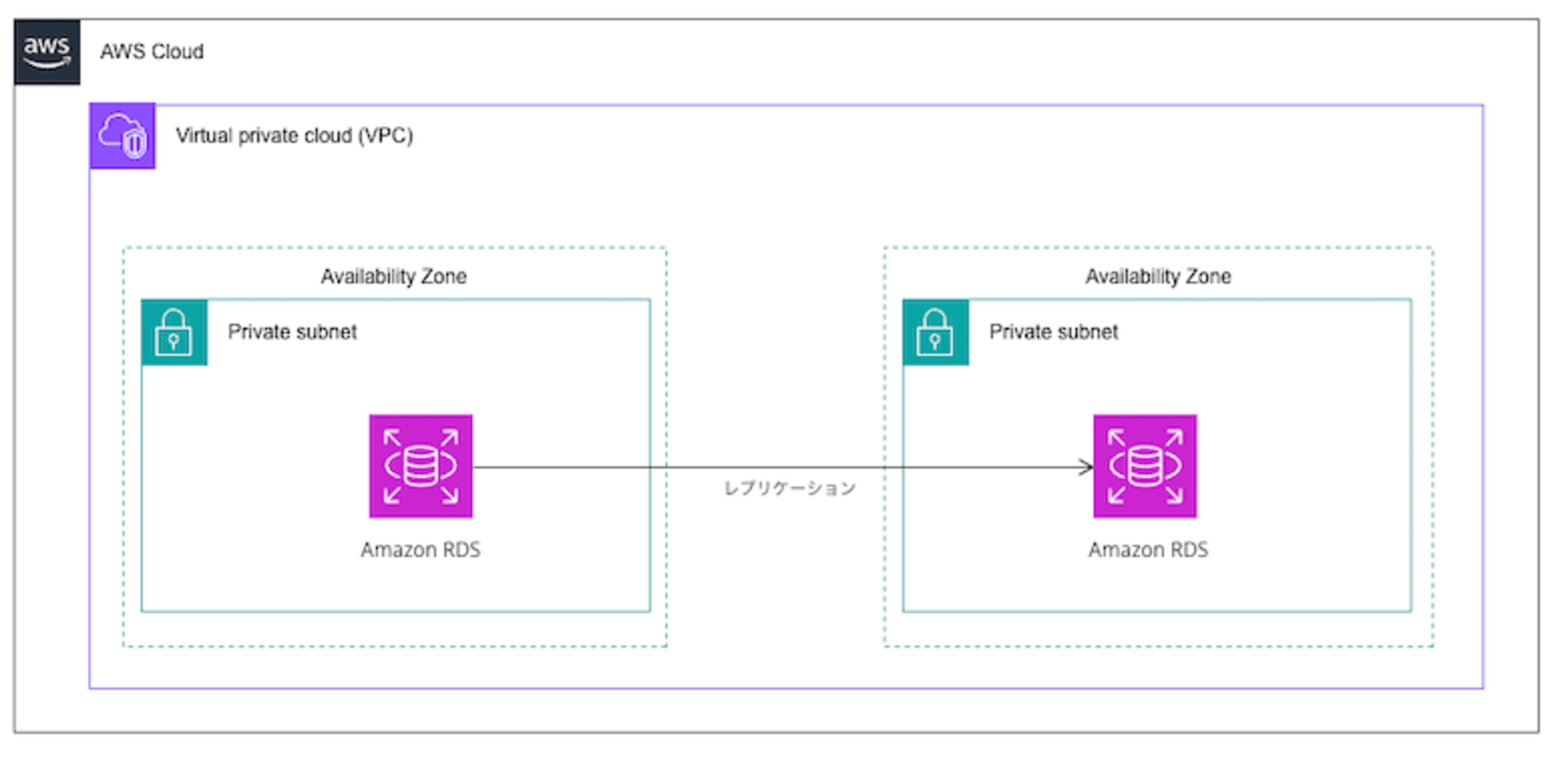
マルチAZでAmazon RDSを配置します。
1. サブネットグループを作成する
まず、データベースをどのサブネットに配置するかを定義する「サブネットグループ」を作成します。
サブネットグループを作成するにはAmazon RDSのコンソールのサイドバーにある「サブネットグループ」を選択します。
続いて、オレンジ色のボタン「DB サブネットグループを作成」を選択します。
名前、説明には後から見てわかりやすい名前を入力、RDS、アベイラビリティーゾーン、サブネットにはRDSの配置先を選択して「作成」をクリックします。
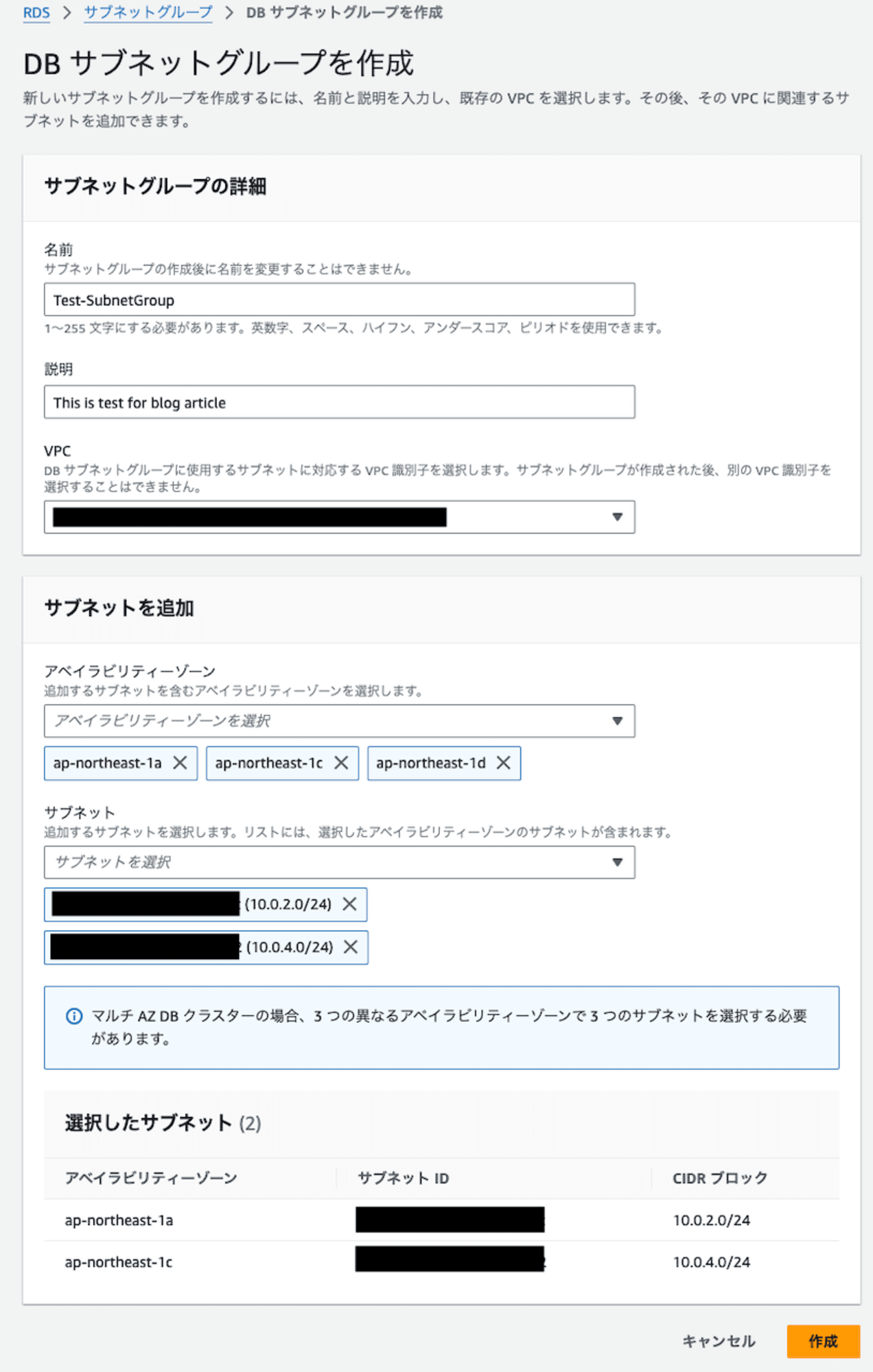
これでサブネットグループの作成は完了です。
2. データベースを作成する
では早速データベースを作成してみましょう!
Amazon RDSコンソールのサイドバー「データベース」を選択後、「データベースの作成」をクリックします。
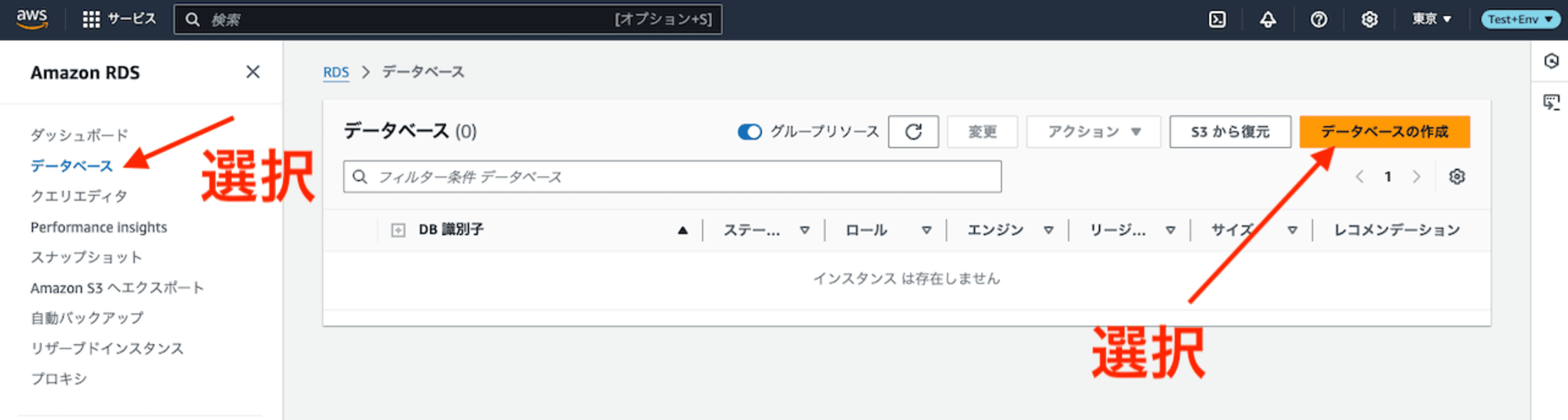
「データベースの作成」を選択した後の流れは具体的に以下のようになっています。
- データベースのエンジン、バージョンを選択
- データベースの配置方法を選択
- データベースの名前、管理者ユーザの設定
- データベースのインスタンスの設定(性能の決定)
- ネットワークの設定
- その他、細かなオプションの設定
では順番に設定していきましょう!
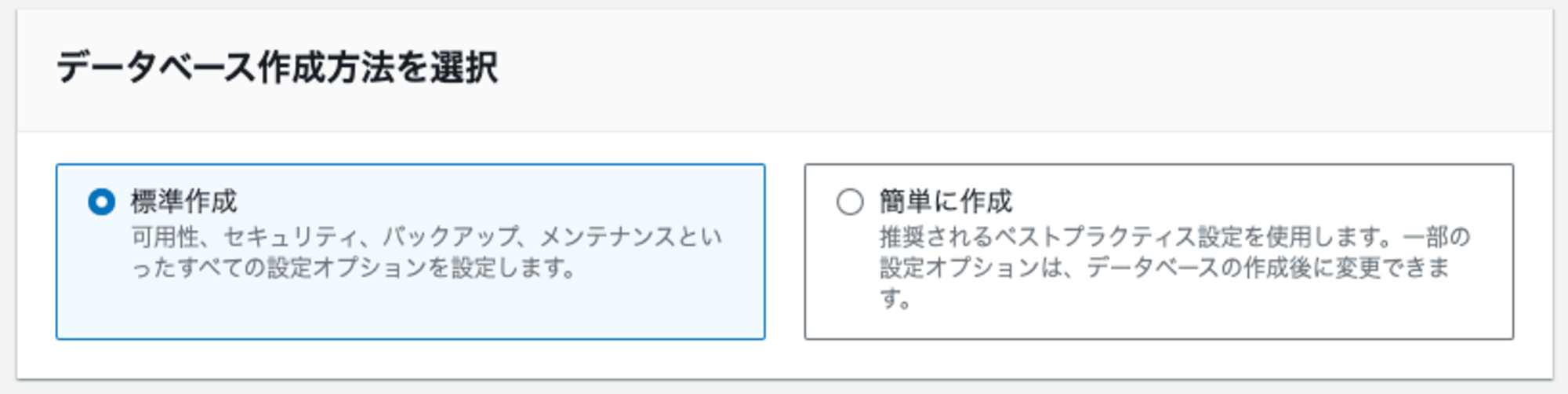
まず、データベース作成方法の選択で「標準選択」「簡単に作成」の2種類がありますが、今回は検証を目的とした設定を行うため「標準作成」を選択します。
続いて、データベースのエンジン、エンジンバージョンを選択していきます。
今回はMySQLで最新のバージョンを選択します。

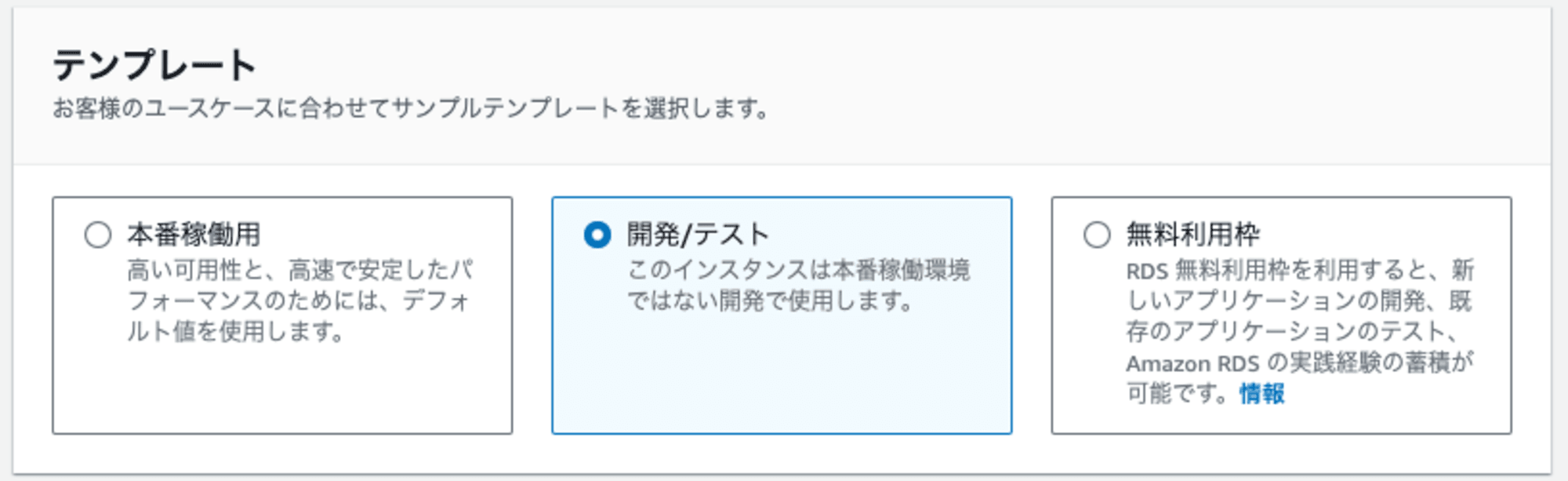
続いて、テンプレートの選択になりますが、「開発/テスト」を選択します。
今回、検証目的のため構築後直ぐにデータベースを削除する、マルチAZ配置をしたいため「開発/テスト」を選択します。
続いて、可用性と耐久性ではデータベースの配置方法を選択します。
選択の詳細については各項目に記載されておりますが、ざっくり説明すると以下のようになります。
| 項目名 | 説明 |
|---|---|
| マルチ AZ DB クラスター | 読み書きできるDBとリードレプリカを2つ作成する、合計3つのDBを複数アベイラビリティーゾーンに作成する方法です。可用性を向上しつつ、読み取り性能を向上させます。 |
| マルチ AZ DB インスタンス | 読み書きできるDBと待機用のDBの合計2つのDBを複数アベイラビリティーゾーンに作成する方法です。待機用のDBはフェイルオーバー用で2つのDBに同時に接続することはできません。片方のDBに障害が発生した際でも、待機用のDBに切り替えることで停止時間を抑えることができます。 |
| 単一の DB インスタンス | 1つのアベイラビリティーゾーンのみにDBを配置する方法です。 |
今回は構成図に沿って、マルチ AZ DB インスタンスを選択します。
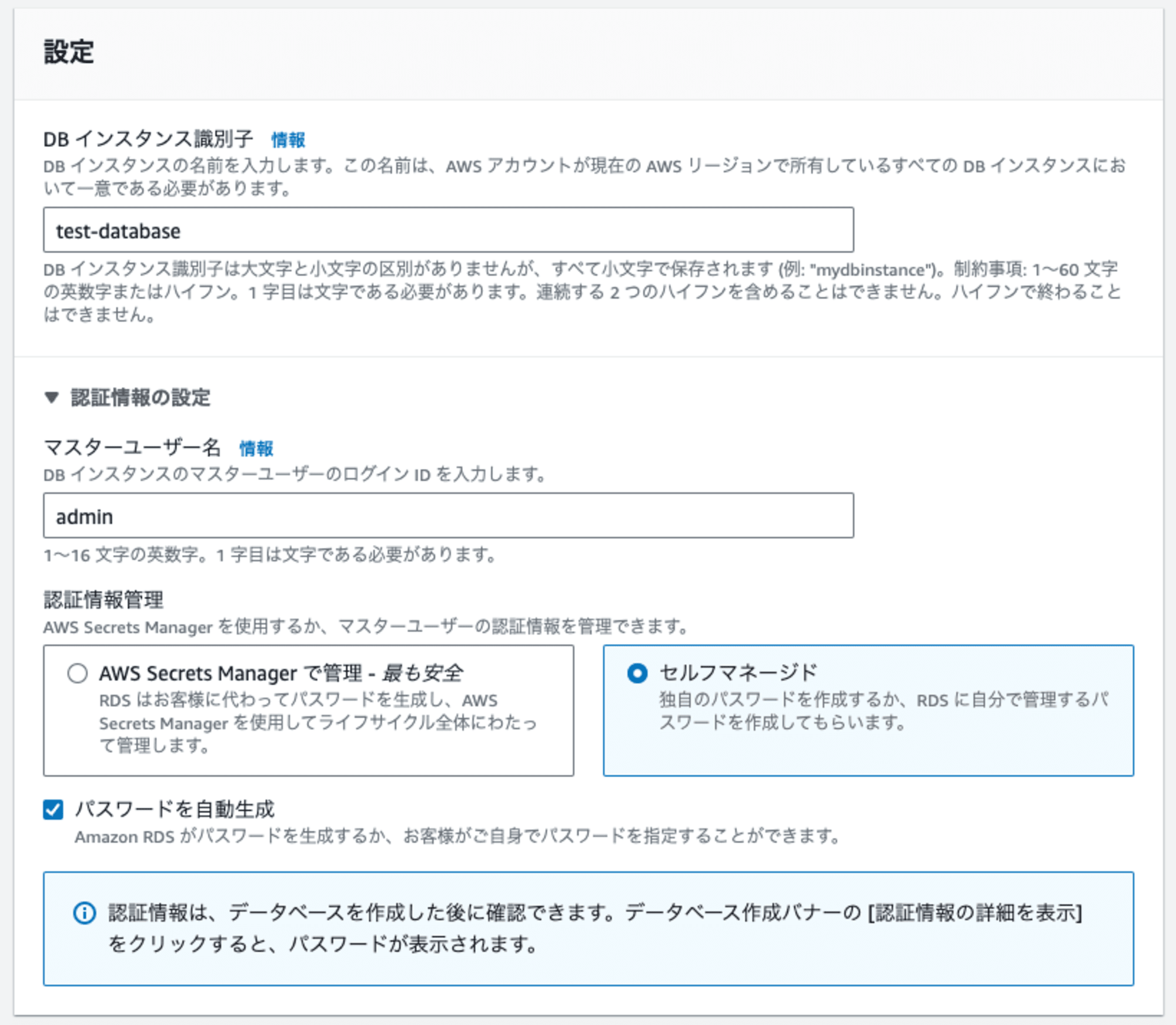
可用性と耐久性の設定が完了したら、データベースの名前、管理者ユーザの設定を行います。
DB インスタンス識別子ではAWS上における識別子(名前)を入力します。
続いて、管理者ユーザ名の指定、認証情報の管理方法を選択します。
AWS Secret Managerを使用することで、パスワードをAWS上で管理したり一定期間ごとにパスワードをローテーションすることができます。
ただし、AWS Secret Managerの利用にはAPIの呼び出しに応じた費用が発生します。詳細な料金については、AWS公式サイトを確認することをお勧めします。
今回は検証用途であり、すぐにデータベースを削除する予定のためセルフマネージドを選択します。
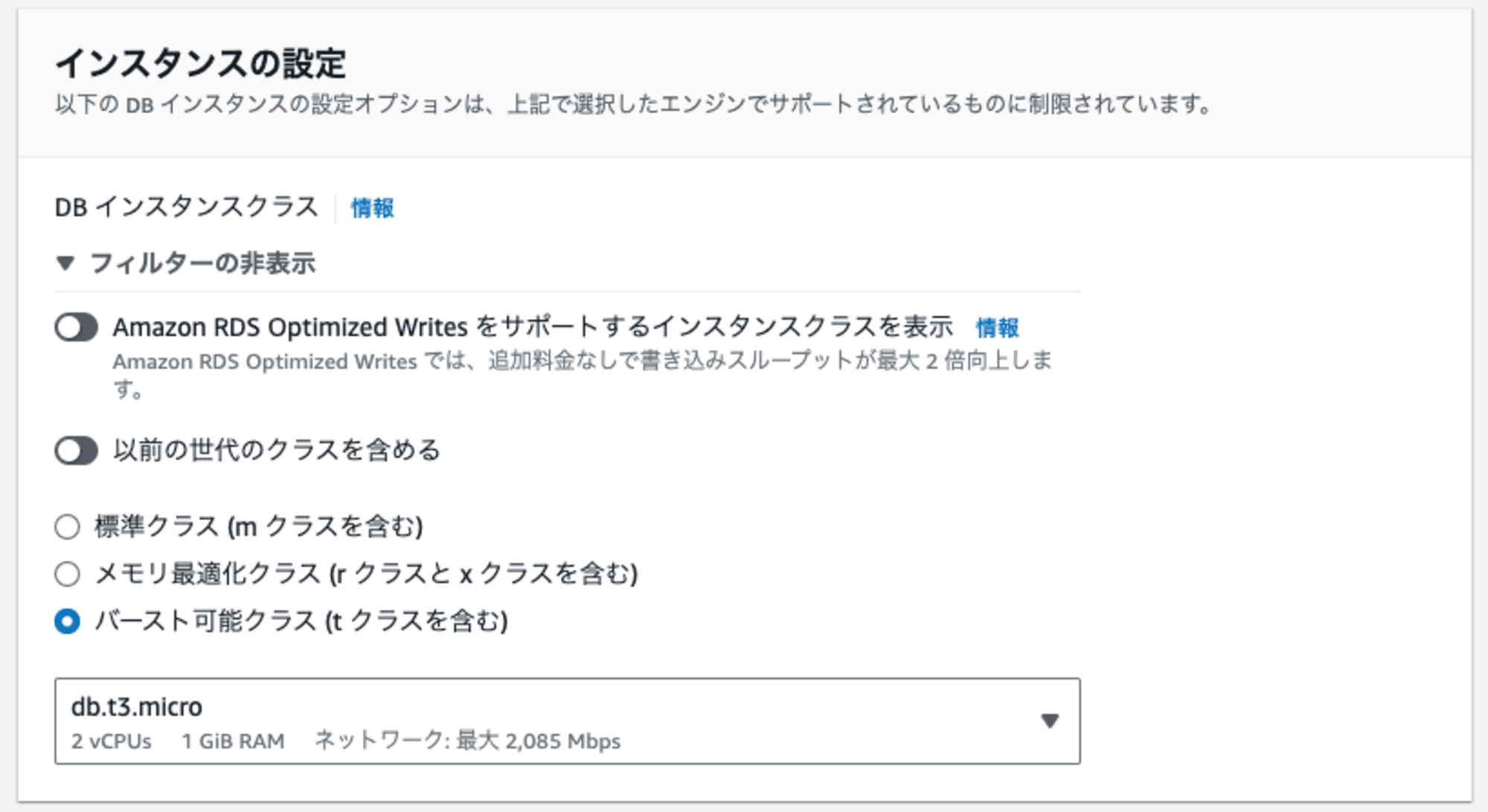
次に、インスタンスの設定をします。
ここではデータベースを稼働させるバックエンドの性能を選択します。
本番環境では要件に沿って設定を行いますが、今回は検証目的かつ学習用とのため、バースト可能クラス(t クラスを含む)を選択後、db.t3.microを選択します。
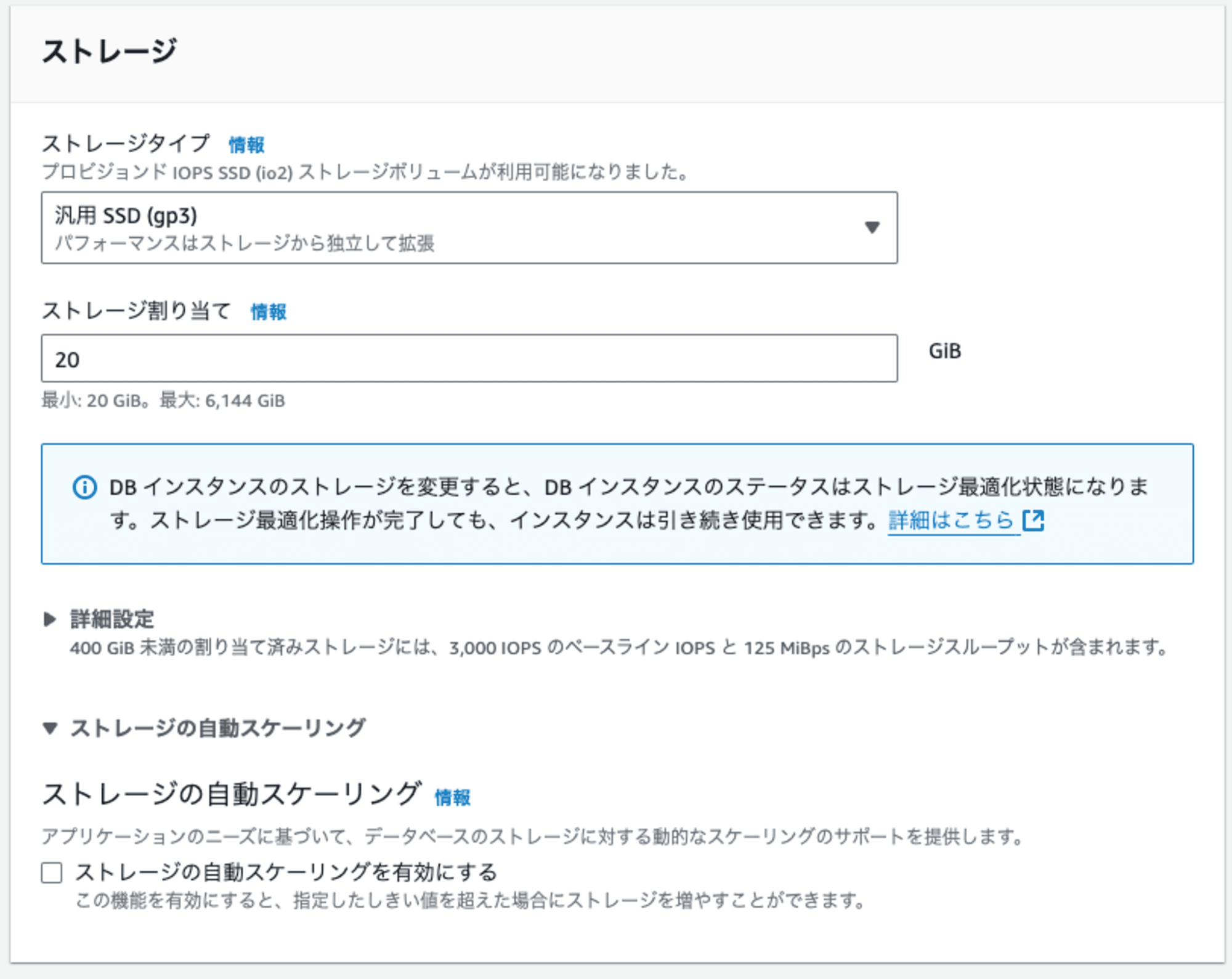
続いて、ストレージの設定をします。
ストレージタイプはI/O要件などにより設定を行います。(今回は汎用SSD (gp3)を使用します。)
また、ストレージ割当量は最小値の20 GiB、容量が不足したときに自動でスケールする「ストレージの自動スケーリング」は無効にします。
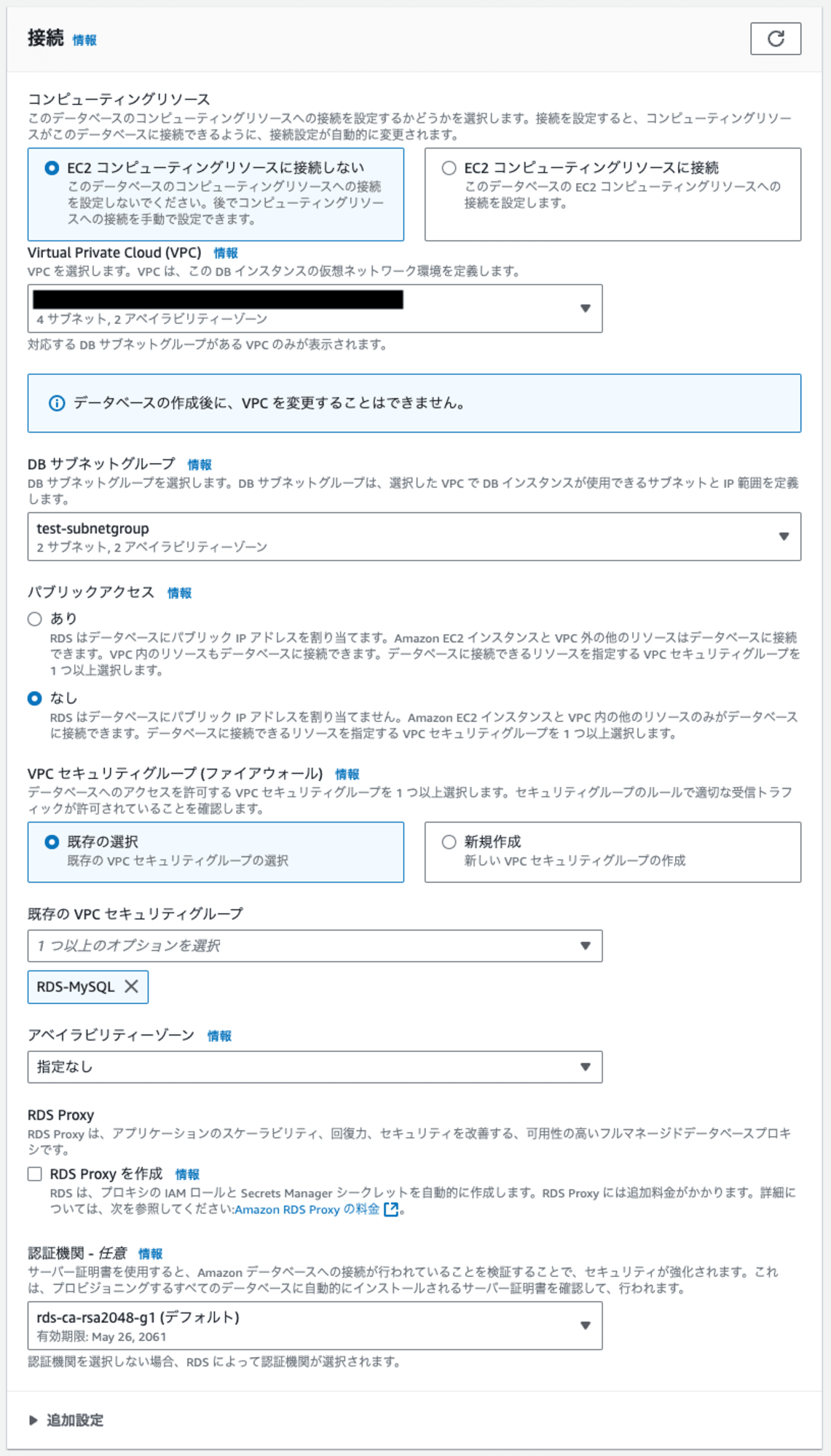
次はネットワークの設定を行います。
重要なポイントはVPC、DBサブネットグループ、 パブリックアクセス、VPC セキュリティグループの4つです。
VPCはデータベースを配置するVPC、DBサブネットグループは配置先となるサブネットを定義したもの(先ほど作成しましたね)、パブリックアクセスはインターネットを介したアクセスの有無、VPC セキュリティグループはファイアウォールの定義を設定します。
そのほか、EC2との接続を構成してくれるコンピューティングリソースや回復力の向上に寄与するRDS Proxy、サーバー証明書などを設定できますが、今回はデフォルト値とします。
最終的に本検証では以下の設定とします。
| 項目名 | 設定値 |
|---|---|
| コンピューティングリソース | EC2 コンピューティングリソースに接続しない |
| Virtual Private Cloud (VPC) | 作成したVPC |
| DB サブネットグループ | 作成したD サブネットグループ |
| パブリックアクセス | なし |
| VPC セキュリティグループ (ファイアウォール) | 作成したVPC セキュリティグループ |
| アベイラビリティーゾーン | 指定なし |
| RDS Proxy | 無効 |
| 認証期間 | デフォルト |
画像でお見せすると以下のようになります。
残りの重要な設定項目を以下に記載します。(記載がないものはデフォルト値です。)
| 大項目 | 小項目 | 設定値 |
|---|---|---|
| データベース認証 | データベース認証オプション | パスワード認証 |
| モニタリング | 拡張モニタリングの有効化 | チェックなし |
| 追加設定 | 自動バックアップを有効にします | チェックあり |
| 暗号を有効化 | チェックあり | |
| AWS KMS キー | (default) aws/rds | |
| 削除保護の有効化 | チェックなし |
設定が完了したら、一番下にあるオレンジ色ボタン「データベースの作成」をクリックします。
3. 接続してみる
しばらくするとデータベースのステータスが利用可能に切り替わります。

この状態になったら準備完了です。実際に接続していきましょう。
CloudShellを開き、以下のコマンドを実行します。途中、パスワードを聞かれるので管理者ユーザのパスワードを入力してEnterキーを押下します。
mysql -h <データベースエンドポイント> -u <管理者ユーザ名> -p
※データベースエンドポイントはデータベース識別子をクリックすると出てくる「接続とセキュリティ」タブから確認できます。
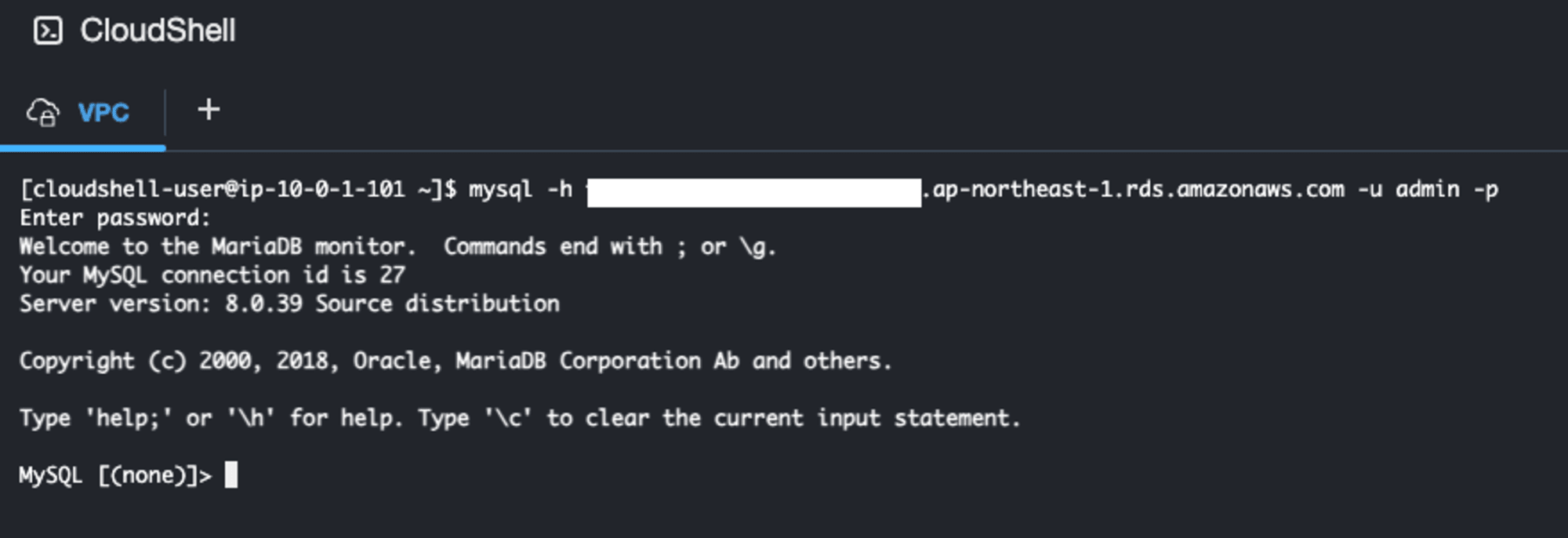
無事に接続できました!
検証が終わったら
接続できることが確認でき、検証が完了したら作成したリソースは削除します。(AWSでは従量課金のため、リソースが存在している状態では課金されます。)
データベースを選択し、「アクション ▼」から「削除」を選択します。
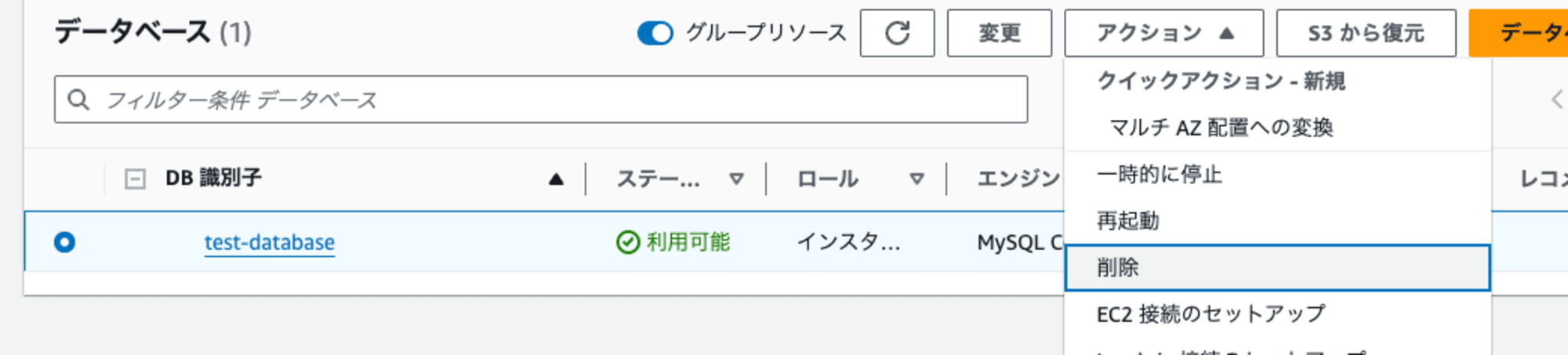
削除前に確認が求められます。
今回は検証用環境でデータの保持は不要のため、最終スナップショット、自動バックアップの保持にはチェックを入れず、確認用文字列を入れて「削除」をクリックします。
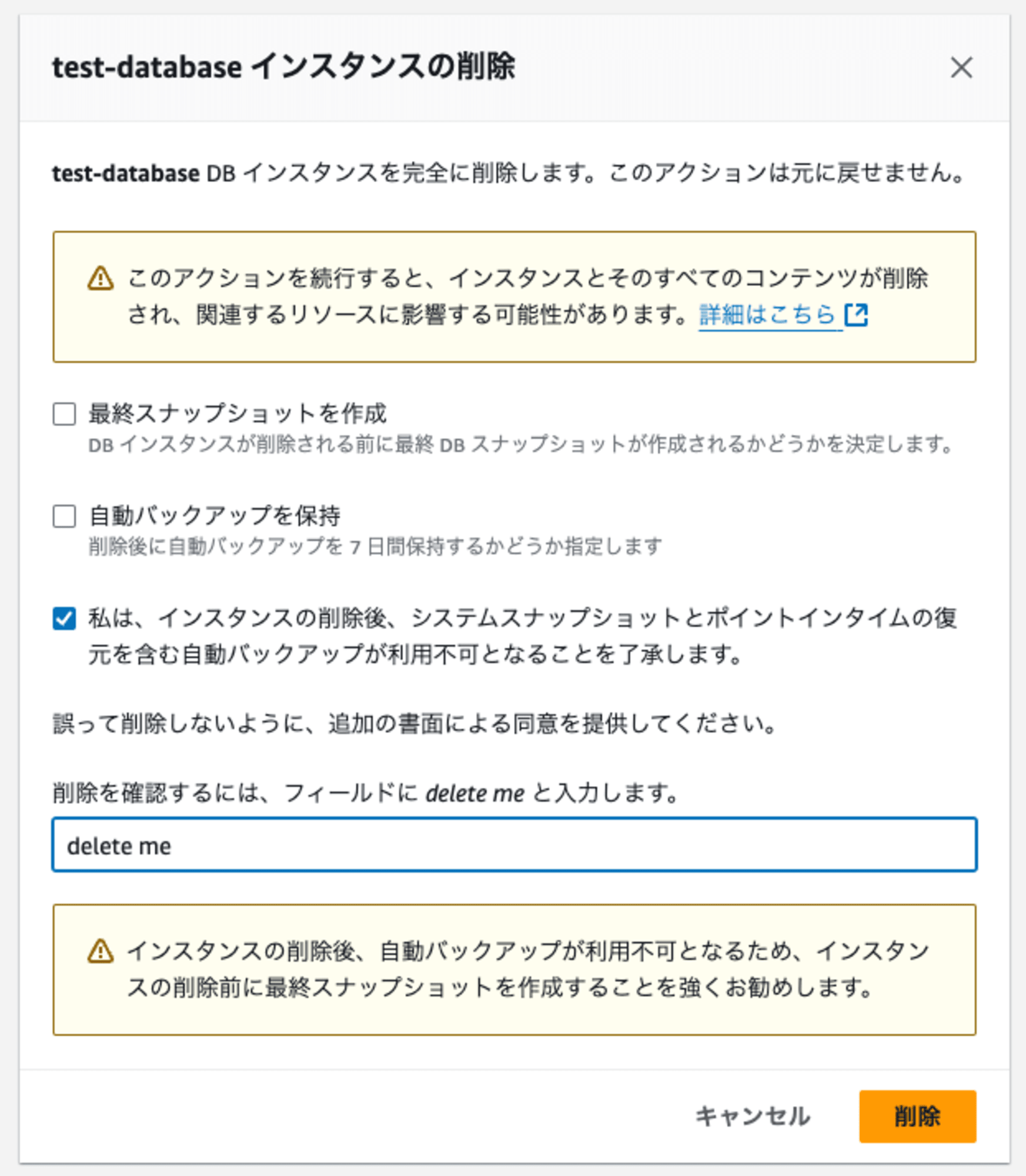
これでAmazon RDSの削除は完了です。
まとめ
今回は改めてAmazon RDSの利点や実際にデータベースを構築してみました。
本来であれば、サーバーにOSをインストールした後、データベースエンジンのインストール、セットアップ、運用・監視。定期的なパッチの適用なバックアップなど全てを管理する必要がありましたが、Amazon RDSを使用することで、インフラ面の構築や監視の負担が軽減されるため、多くのケースで運用コストの削減が期待できるのではないでしょうか。
また、可用性や耐障害性の観点でも非常に簡単にデータベースのレプリケーション、バックアップなどができ、特に本番環境では有用だと思います。
ぜひ皆さんも使ってみてはいかがでしょうか。
今回の記事は以上となります。お読みいただきありがとうございました。




![[アップデート]Network Load Balancer(NLB)でアベイラビリティーゾーンの削除がサポートされました](https://images.ctfassets.net/ct0aopd36mqt/wp-thumbnail-f650a3011b384cc3781610c17755bc71/c37c67c9bc40b72e6dce1a49f4153283/elastic-load-balancing)

![[アップデート] AWS Lambda の CloudWatch Application Signals サポートランタイムに Java と .NET も追加されました](https://images.ctfassets.net/ct0aopd36mqt/wp-thumbnail-484d8afca1cbe50513cd4d6738af2960/fa0838fa40f247093d532945fc785e88/aws-lambda)
